
こんにちは
最近のAI技術の進歩には、目を見張るものはありますねー
数ヶ月まえには一般ユーザーにはできなかった作業も、気がつけば誰でも簡単に(一部)無料で出ちゃうことが多々あります。
最近驚いたのは、音声ファイルから議事録を作成する機能。
特に録音も鮮明というわけでもなかったのにもかかわらず、まじで精度高かったですよ!!
そこで改めて「AIの進歩のスピード」に恐怖したのです。
AIサービスになにか尋ねる→ネットワーク上にある情報から質問に対する回答を考え出力してくれる。
まあ、簡単に言うとそんな作業。
しかし、これは使っている自分のPCの処理ではなく、接続しているサーバー側が処理しているのです。
そこで「一体この膨大な情報の処理をどんなスペックのサーバーが行っているんだ?」ということが気になり。
それこそAI先生に質問してみました。
質問は→「AIサービス提供業者のハードウエアとはどのくらいすごいものを使用しているのか?CPU,GPUなどのスペックも合わせて教えて」です。
こんなに適当な、しかも日本語としてもどうなんだよ(汗
といった質問でも、きっちり回答してくれました。
どうぞ!↓
AIサービス提供業者が利用するハードウェアは、大量のデータを高速に処理し、複雑な計算を効率的に実行するために、極めて高性能なものが採用されています。特に、機械学習モデルの学習や推論には、専門的なハードウェアが不可欠です。
AIサービスを支える主要ハードウェア
AIサービスの提供には、主に以下のようなハードウェアが利用されます。これらは通常、大規模なデータセンターに設置され、クラウドサービスとして提供されることも一般的です。
1. GPU (Graphics Processing Unit:グラフィックス処理ユニット) 🚀
AI、特にディープラーニングにおいて最も重要なコンポーネントの一つです。GPUは、大量の計算を並列処理する能力に長けており、これはAIモデルの学習や推論に非常に適しています。
- 代表的なメーカー・モデル:
- NVIDIA: AI分野で圧倒的なシェアを誇ります。
- データセンター向け: NVIDIA A100, H100, GH200 Grace Hopper Superchip など。これらは、数千から数万のCUDAコア、数十GBから数百GBの広帯域幅メモリ (HBM) を搭載し、極めて高い演算性能 (ペタフロップス級) を実現します。例えば、NVIDIA DGX H100 システムは、8基のH100 GPUを搭載し、AIの学習や大規模な計算処理に特化しています。
- ワークステーション・小規模サーバー向け: NVIDIA RTXシリーズ (例: RTX 6000 Ada Generation) なども、高度なAI開発に利用されます。
- スペックの特徴:
- CUDAコア/Tensorコア: 並列処理を行うための演算ユニット。Tensorコアは、AIの計算に特化したユニットで、混合精度計算などを高速に実行できます。
- VRAM (ビデオメモリ): 大量の学習データやモデルパラメータを保持するために、数十GBから数百GBの大容量かつ高速なメモリが搭載されます。メモリ帯域幅も非常に重要です。
- 演算性能: FLOPS (Floating point Operations Per Second) で表され、特に半精度 (FP16) や8ビット整数 (INT8) での性能が重視されます。
2. CPU (Central Processing Unit:中央処理装置) 🧠
GPUが主要な計算処理を担う一方で、CPUも依然として重要な役割を果たします。
- 役割:
- システム全体の制御
- データの入出力管理
- 学習データの前処理
- GPUへのタスク割り当て
- 一部のAIアルゴリズムの実行
- スペックの特徴:
- コア数・スレッド数: 多数のコアを搭載したサーバー向けCPU (例: Intel Xeon Scalable Processors, AMD EPYC) が使用されます。これにより、複数のタスクを効率的に処理できます。
- クロック周波数: 高いクロック周波数も重要ですが、AI処理においてはコア数や並列処理能力がより重視される傾向があります。
- キャッシュメモリ: 大容量のキャッシュメモリは、データアクセスの高速化に貢献します。
3. メモリ (RAM: Random Access Memory) 💾
AIモデルの学習や大規模なデータ処理には、大容量のシステムメモリが必要です。
- スペックの特徴:
- 容量: 数百GBから数TB単位のメモリが搭載されることも珍しくありません。これにより、巨大なデータセットをメモリ上に展開し、高速なアクセスを可能にします。
- 速度・帯域幅: DDR4やDDR5といった高速なメモリモジュールが使用され、CPUとGPU間のデータ転送効率を高めます。ECC (Error Correcting Code) メモリも、システムの安定性確保のために重要です。
4. ストレージ 💽
学習データや生成されたモデルを保存するために、高速かつ大容量のストレージが求められます。
- スペックの特徴:
- NVMe SSD (Non-Volatile Memory Express Solid State Drive): 従来のSATA接続SSDよりもはるかに高速な読み書き性能を持つNVMe SSDが主流です。これにより、学習データの読み込み時間を大幅に短縮できます。
- 容量: 数TBから数十TB、あるいはペタバイト級のストレージシステムが構築されることもあります。
5. ネットワーク 🌐
複数のサーバーやGPU間で大量のデータを高速にやり取りするために、高性能なネットワーク機器が不可欠です。
- スペックの特徴:
- InfiniBand: 低遅延かつ高帯域幅を実現するインターコネクト技術で、大規模なGPUクラスタなどで広く採用されています。
- 高速イーサネット: 100Gbpsや200Gbps、さらには400Gbpsといった高速イーサネットも利用されます。
- RDMA (Remote Direct Memory Access): CPUを介さずにサーバー間のメモリに直接アクセスする技術で、通信遅延を削減します。
6. TPU (Tensor Processing Unit) など専用プロセッサ ✨
Googleなどが自社開発するAI処理に特化したASIC (Application Specific Integrated Circuit) です。
- 特徴:
- 特定のAIワークロード (特に推論処理) において、GPUを上回る電力効率や処理性能を発揮する場合があります。
- Google Cloudなどで利用可能です。例えば、Google TPU v5p や最新の Ironwood といったモデルは、極めて高い演算性能とメモリ帯域幅を誇ります。
まとめ
AIサービス提供業者は、最先端のAIモデルを効率的に学習・運用するために、NVIDIAの最新GPUを中心とした超高性能なハードウェア群を駆使しています。CPU、メモリ、ストレージ、ネットワークといった周辺コンポーネントも、AI処理のボトルネックとならないよう、非常に高いスペックのものが選定されます。また、Googleのように独自のAIプロセッサを開発・活用する動きも見られます。これらのハードウェアは、常に進化を続けており、AI技術の発展を支える基盤となっています。
つまり
AIサービス提供業者は、最先端のAIモデルを効率的に学習・運用するために、NVIDIAの最新GPUを中心とした超高性能なハードウェア群を駆使しています。
から、NVIDIAの株価が近年うなぎのぼりなのです(基本的には)。
それ以前からも仮想通貨のマイニングに際してNVIDIAのGPUが一時期市場から消えたっ記憶があります。(加減を知らないチャイニーが買い占めたんだろうね・・・)
↓2025/06/03 現在 NVIDIA 過去5年株価チャート
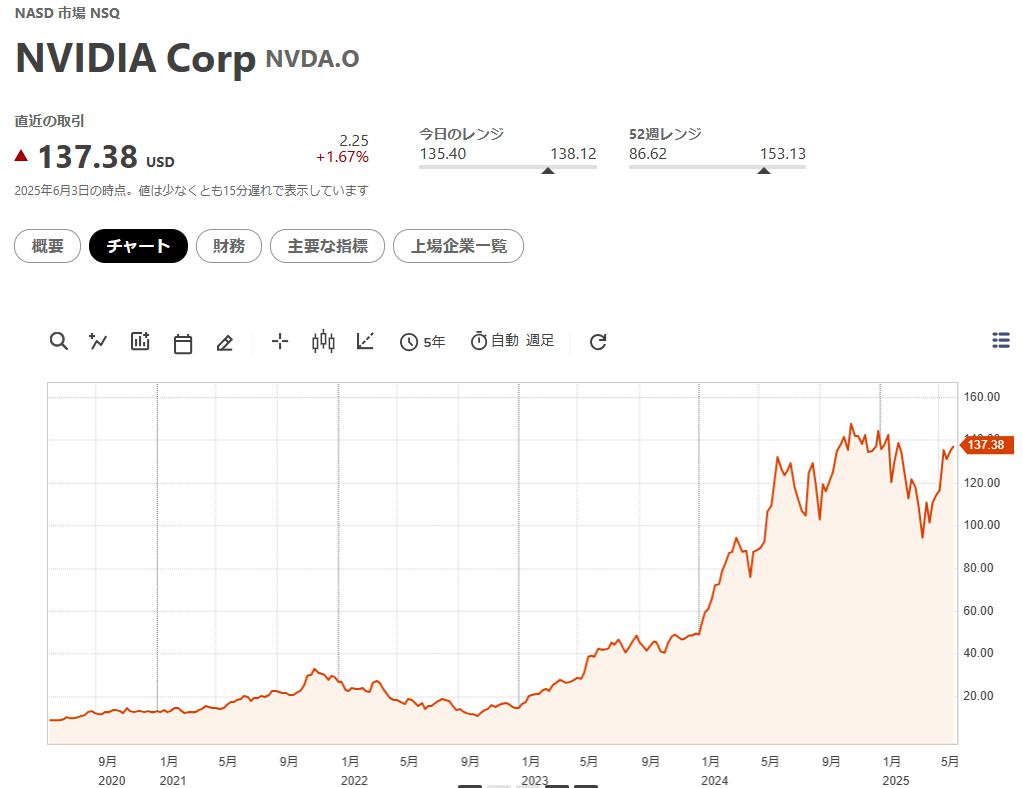
直近2025年2月7日に開かれた日米首脳会談後の記者会見で、唐突にトランプ米大統領が以下のように表明しました。
貿易相手国と同様の関税を課す「相互関税」を、「来週の月曜日か火曜日に発表するつもりだ」と。このたあたりから、NVIDIAの株価は下落傾向ですが、数年先まではこの会社の培ってきたGPUの性能を上回る企業は出てこない(気がする)から、これからも上がって行くんだろうなー?と思えちゃいますよねー
投資は自己責任でw
FIN